
The inclinometer import type can be used to import data for the feature type Inclinometer.
Data |
Notes |
Feature Name |
New features can be created automatically, observations for already existing features will be appended to that feature. |
Type specific observation data |
Depth, deviation in A, deviation in B, Zero-reading and Erroneous flag |
Table 1: Data that can be imported by this import type
The file format expected by this import type is a text file structured in lines and columns. The text file can include Unicode characters encoded as UTF-8 (which is backward compatible to ANSI with codepage 65001). The file may use a BOM (Unicode byte order mark) to specify the byte order of the character encoding.
A line in the source file must be terminated by line feed character (U+000A, UTF-8: 0x0A, typical for Unix, Linux, Android, Mac OS X, BSD, and other operating systems), a carriage return (U+000D, UTF-8: 0x0D typical for Mac OS till Version 9 and other operating systems), or a carriage return immediately followed by a line feed (typical for Windows operating systems).
Leading and trailing white space characters (see table 2) will be automatically trimmed from each line. If the column separator is set to tab (U+0009) tabs will not be trimmed. The first character of a line is defined as the first non-white space character, the last character as the last not white space character.
Lines where the first character is a # (U+0023, UTF-8: 0x23) are treated as comment lines and will be ignored. If the # is contained in a line but not the first character in the line it will be treated as data. Empty lines (after trimming) except the first non-comment line after the first header line are ignored.
Each non-comment and non-empty line is separated into cells by the column delimiter character. The column delimiter character can be set in the import type's settings. Only one column delimiter character is allowed between two columns, i.e. for n columns you need exactly n-1 column delimiters, and column n is the column after the n-1th column delimiter.
The first two non-comment and non-empty lines are treated as header lines. Header lines contain processing information for the import. The first header line is used to define the contents of each column by specifying a column content identifier in each cell. This column content identifier is used by the Application Server to match the data in that column to some characteristic of the inclinometer feature or observation. Columns with a column content identifier that is not recognized by the Application Server are ignored. The second header line is used to define the unit for numeric values if these numeric values are matched against a quantity property in the observation's type specific data property structure.
Table 2 shows the column content identifiers that must be present for this import type. Since the column headers in header line 1 define the contents of each column, the sequence of columns is not important
Column content identifier |
Description |
FEATURE |
Identifying name of the inclinometer feature |
OBSERVATION_SAMPLINGTIMESTAMP |
Sampling timestamp of the observation |
DEPTH |
Depth of the observed value |
A |
Deviation in A |
B |
Deviation in B |
ZEROREADING |
Zero reading flag |
ERRONEOUS |
Erroneous flag |
Table 2 column content identifiers that must be present for this import type
|
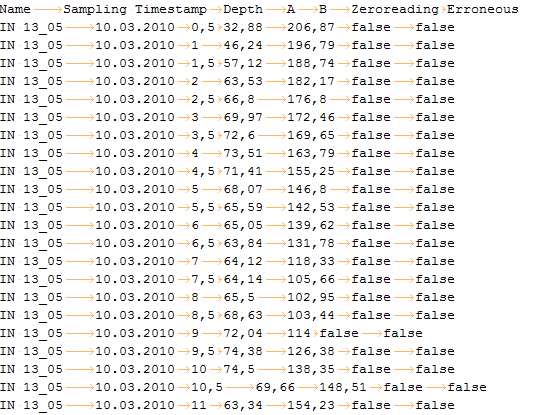
Figure 1: Example for an import source file used to import inclinometer data. Note the orange arrows show tabs.
